The Model’s Architecture (in the Example of DNN)
This section will provide details for Model 1, Model 2 and Model 3 mentioned in the paper. To recap, Model and Model 2 both use a machine learning algorithm (MLA) to identify and remove non-chord tones (NCTs). The details of this algorithm is illustrated below.
For input and output encoding, I use the one-hot encoding method. The example uses 12-d pitch class (in the order of C, C#/Db, D, D#/Eb, etc.) to indicate the current slice (highlighted in the solid line), and the window size 1 to add the previous slice and the following slice (highlighted in the dashed line) as context, along with 12-d pitch class for output indicating which pitch classes are NCTs, the resulting model’s architecture looks like this:
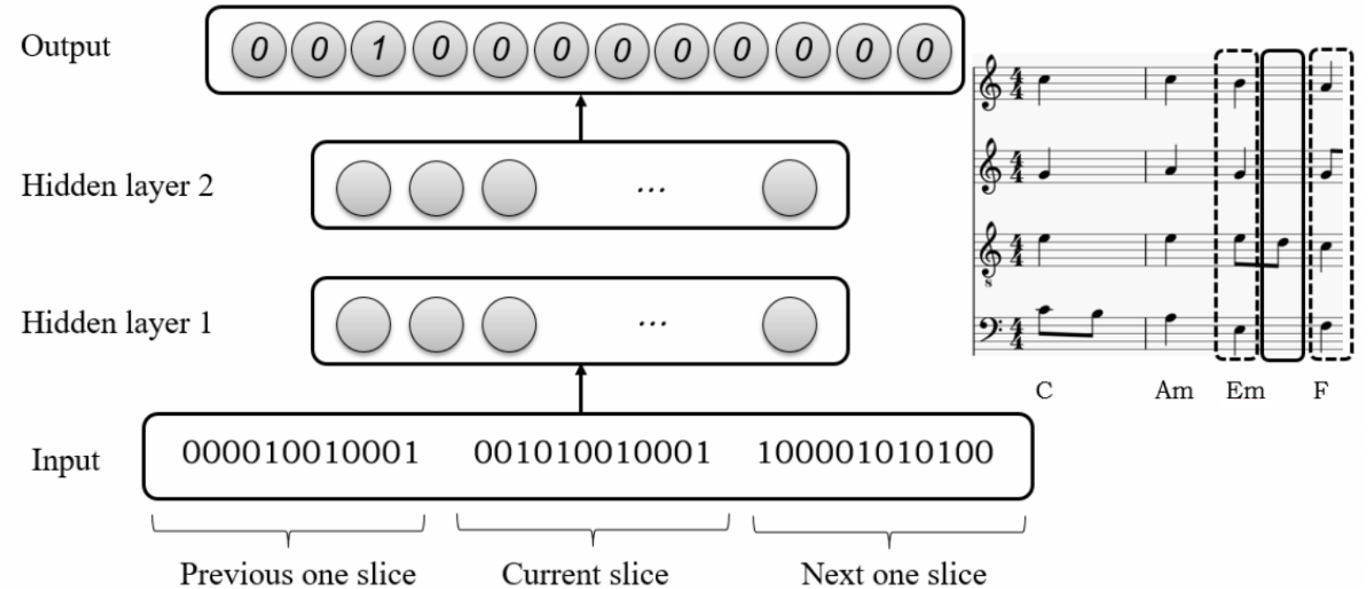
Then, Model 2 uses another machine learning algorithm (MLB) to infer chord labels (CL) from the remaining chord tones. Model 1 uses a generic heuristic algorithm (see this page at the section of “Overview of the Chord Inferring Algorithm” for more details) to do so.
For Model 2, the input vector is almost identical to the one shown in the example, the only difference is that since pitch class D has been identified as NCT (from the output vector of this example), it will be removed from the input vector (so that the encodings of the current slice will be 000010010001 instead of 001010010001). Another difference for MLB is that the output vector is not 12-d anymore. In fact, its dimension equals to the sum of all chords we want to identify, and the output vector will trigger only one bit, which will be the predicted chord label.
Model 3 uses the input vector of MLA and the output vector of MLB, since it directly predict chord labels from the musical surface, without removing any NCTs.